How do we make sure that a Large Language Model (LLM) understands a task, and completes it as accurately as possible?
If you’ve experimented yourself, or read the advice of major LLM providers (such as these guides from Anthropic, Google, Meta, Microsoft and OpenAI), you’ll know there’s a common principle. Communicate with LLMs like you would a human.
To get the best results:
- give well-explained instructions in natural language
- break complex tasks into smaller steps
- include helpful examples and context
- allow time to ‘reason’ through a problem in stages
- provide well-organised and structured source material
- test and iterate instructions until they’re consistently well-understood
- review, edit and quality assure content throughout the process
I’m not the first to point out that these are among the many skills of a content designer. As a Lead Content Designer in Justice Digital, I think our profession can play a vital role in exploring use cases, techniques and quality safeguards for these natural language tools. Not to do the things we already do well, but those we never could before.
This blog post describes one experimental example: combining content design techniques with a Large Language Model to extract insights from service assessment reports.
The opportunity: service assessment reports
When a panel of experts conducts a service assessment, they write up a report for the team they’ve assessed. The report describes how the service team has met or not met the Service Standard, and recommends next steps.
Reports for services that meet the threshold for a cross-government assessment are publicly available for anyone to read, published by the Central Digital and Data Office (CDDO).
By the end of 2023, CDDO had published 365 of these reports, of which 196 applied the latest version of the Service Standard (or could easily be mapped to it). This is a huge library of practical insight for anyone preparing for a service assessment, whether in their own department or cross-government.
The challenge: it’s a lot to read
Large knowledge bases (such as a library of legal cases or medical papers) aren’t intended to be read cover-to-cover by any one person, of course.
The subset of 196 reports alone contains around half a million words, longer than the Lord of the Rings Trilogy. Anyone who diligently read the entirety would surely achieve Gandalf-like wisdom on the subject of service assessments (“one Standard to rule them all” etc).
And there’s no easy way to accurately summarise half a million words with any LLM. Even if there existed such a large context window (the amount of text a language model can ‘read’ at once), accuracy - like digestion - is compromised if you cram in too much at once. Shorter texts tend to be more accurately summarised than very lengthy ones, which usually need ‘chunking’ into segments, or atomising into a kind of semantic cloud (a ‘vector database’). When the LLM automatically does this carving up for us, we lose more control over the process, which becomes increasingly opaque and error-prone.
A hybrid approach
Regardless of the current technology considerations, a straightforward summary of 196 reports wouldn’t be very useful. To improve the results, a lightweight technical approach is combined with elements of content design.
The step-by-step process:
1. Gather the source content. We could do this manually, merging every assessment report into a giant document, but it would be very inefficient and time-consuming. It’s much faster and more scalable to extract the text via the GOV.UK Content API. We first export the full list of report URLs from the GOV.UK Content Data tool, and can then use some relatively simple code (Python, in this case) to run through the URLs and retrieve all the corresponding body HTML via the API.
2. Segment the source content. We now need to break down the reports into their component content parts. The consistent headers that appear in each report (eg.“1. Understand users and their needs” or “What the team has done well”) can helpfully function as delimiters. With these slice points, we can segment the text into a structured dataset (stored in a JSON file, for instance), like Lego bricks that we can rearrange.
3. Rearrange the content. The reports are originally organised by service, each structured around the 14 points on the Service Standard. Working with the structured data, we can reverse that, grouping the content around the Service Standard points instead. For example, we can group all the descriptions of what teams did to meet “Understand users and their needs”, allowing us to see in one place everything that successful teams did. And the opposite: all the things teams needed to explore when this point was not met.
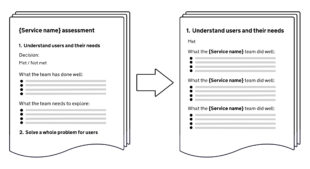
4. Iterate LLM instructions. With the content segmented into Service Standard-themed chunks, we can now test and refine various instructions (or ‘prompts’) for our LLM of choice, drawing out and formatting insights in different ways. For instance, for each point on the Service Standard we can explore:
- what strategies or actions did teams take that met the Standard (grouped broadly by frequency under ‘All teams’, ‘Most teams’, ‘Many teams’, ‘Some teams’)?
- which team might serve as an exemplar, with the strongest positive sentiment from the panel and the most useful detail?
- what were the most common reasons for teams not meeting the Standard?
- what were the most common recommendations for next steps?
- what were some unique or innovative things that teams tried?
We need to iterate our instructions to constrain the output, ensuring it’s as consistent, reliable and easy to read as possible. Many LLMs allow the creation of a ‘system prompt’, enabling us to provide persistent rules around format, length, style and faithful representation of source material (to minimise LLM ‘hallucinations’). This is then combined with specific task prompts for each insight being explored.
A content design perspective is helpful to define these types of rules and instructions, minimising ambiguity and optimising the output’s readability.
5. Collate the outputs into a single document. The idea was to summarise insights from 196 reports into something a single individual could feasibly digest. So once confident that our various instructions produce consistent results on sample tests, we’re ready to run them on every chunk of the segmented content. We then bring the outputs all together into a single document, and format it as a guide that can be read in full or easily scanned for useful nuggets.
6. Quality assure the output. The initial LLM output needs extensive manual review and clean-up. This includes:
- carefully reviewing to make sure it reflects what we know is true about the Service Standard and assessments
- cross-checking with the source material, particularly any claims that seem unusual
- refining the style, readability and clarity (LLMs typically struggle to apply detailed style guides, which can be highly context-dependent, full of nuance and exceptions)
- condensing further to remove duplication or redundancy (the LLM could make recommendations here, but a human will ensure reliability and accuracy)
The result
You can read the output of this experiment in this guide: How teams passed cross-government service assessments (and why some did not)
This guide is no substitute for the Service Manual, of course, or a replacement for all the valuable detail in individual service assessment reports. But it gives us an impression of the hard work across government to develop great services, and provides an additional reference for anyone preparing for a service assessment.
Next steps
This is a proof of concept, with the limited scope of a personal project. To more closely follow a true design process, it would be a multidisciplinary effort that engaged real users, such as teams preparing for a service assessment. What insights would they find most useful? Would it be helpful to group the reports by development stage (discovery, alpha, beta, live) before summarisation? Do people trust information that’s ‘co-authored’ by LLMs?
Content maintenance and continuous improvement are also important, particularly as LLM capabilities improve and new reports are published. LLMs might assist by identifying new information to integrate into existing summaries, and recommending how to do so without continually growing the word count.
If your team is exploring similar projects, it’s a good idea to bring in content design expertise as early as possible. Content designers can offer strategic advice, help to design and quality assure the end-to-end process, and sometimes - just as importantly - identify where human effort alone would be more effective!

1 comment
Comment by Vicky posted on
This is interesting and a great use of an LLM on both open and fairly well curated data. I'd love to see a version that splits across phases (as the recommendations do vary) and also a version that did examples with internal assessments, which I think could be quite different, both in the recommendations but also even if the types of recommendations change.