Across the country, 24 legal tribunals publish public decisions on a regular basis. These decisions not only need publishing, but also storing and ‘made searchable'.
Well, it’s the tribunals database team’s job to ask what manner of clever product could make that process more human and easier to use.
With these public decisions cropping up from legal areas as diverse as employment, immigration and freedom of information, it would indeed have to be a versatile little beast. A product that respected the needs of each jurisdiction and its users while also giving HM Courts & Tribunals Service the ability to ‘own’ a finished product. And a product that brings all jurisdictions’ data together in one place.
Do we all get it?
As with anything, we needed to have absorbed the problem in its entirety before even thinking about the best solution. Led by user researcher Andrea Lewis, we jumped in with both feet, meeting users face-to-face to find out what it was all about.
We discovered users ranged from the judge Googling landmark cases, to the charity worker struggling to find decisions on an asylum case, to a husband searching documentation about his wife’s case.
Tribunal ecosystem
At the same time, we visualised the entire ‘ecosystem’ of tribunals and their associated databases. This was vital to allow us to explore and understand the challenge fully. Only then could we come up with the necessary steps to iterate towards a great final product.

Moving on
As we move from the useful phase of research and discovery into prototyping, we’re beginning to focus testing our solution with users, rather than jumping in with a fixed solution.
We thought we should prototype early then test prototypes with a relatively high-level of fidelity. And do this not only for each jurisdiction but also for the cross-jurisdictional needs that unify our user groups. Our prototype will also generate traction, get buy-in and make our project visible to stakeholders.
Fail fast, succeed early
Equipped with sketchboard and paper, we bounced all sorts of ideas around within the project team. However, we soon realised that, in order to get faithful responses from our users, we needed to combine our prototype with real data. Data was a fundamental part of our product, so couldn't be considered separate to user interaction.
Researching, designing, front and back end developing, we moved forward toward a working testable prototype that demonstrates our vision to users, whilst acting as a stimulus to gather feedback that can inform our development from a very user centred perspective. And it’s coming along nicely.
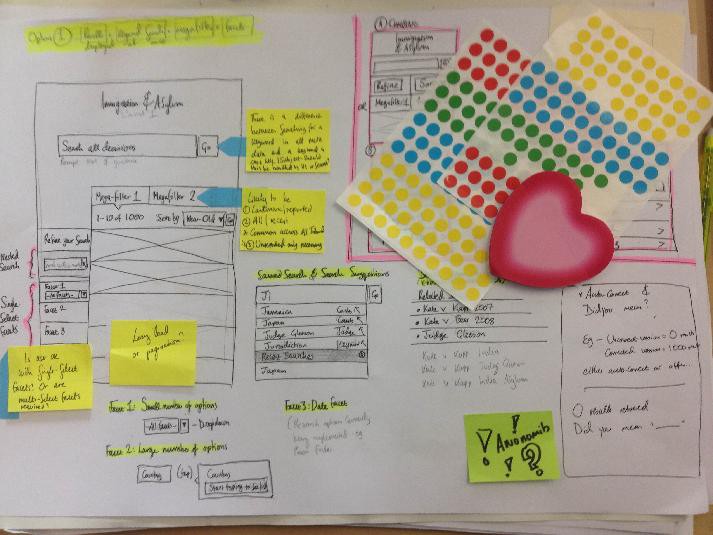
Look at this, folks
We’re looking forward to getting our prototype in front of the people who will be using it – judges, barristers, legal professionals, back-office staff and members of the general public.
So, over the coming weeks, we’re set to:
- identify test subjects
- define the initial working prototype’s level of fidelity
- visualise our users’ needs to drive development in the coming sprints
Each week we’re getting closer to the finished tribunals prototype. But what will it look like? Only our users can really guide us toward that.
But we’re well on our way…

1 comment
Comment by Daniela Tzvetkova, former MOJ Digital Services Product & Service Manager posted on
Kate
Welcome to the MOJ Digital Services!
As someone who worked as a Product and Service Manager on Tribunals decisions database(s) for a year, here's my advice. I hope it can be of help.
The main challenge, (which is rather trivial for an experienced developer / architect), that Tribunals decisions current 'silos' pose, is the data model and porting the legacy data models for 12 databases (and additional 13 'empty shell' future databases!) into a common, over-arching "tribunals decisions" data model. This work was nearly complete in June 2014. I am surprised there is no mention of this in the Discovery findings. How are you addressing this issue and how are you avoiding duplication of the already finished data model work?
The main remaining piece of work after you finish go Live with all tribunals decisions, is switching to something like ElasticSearch or SOLR to replace the postgresql search for better google-like search user experience.
If you continue the work where we stopped in June 2014 you could be done by early 2015 with all tribunals, assuming you have the right developers on your team.
Good luck with tribunals and feel free to contact me at @daulfn