We’re changing the way we run digital services to make sure they're sustainable in the long term and we can keep improving them.
We're responsible for a wide range of services and don't always have the luxury of having dedicated delivery teams for every project. We have to shift our focus from service to service as new ones come along, without losing sight of what we've already created.
Sustaining services
We don't want to think about this in terms of simply 'supporting' a service, after we've 'delivered' it.
'Sustaining' is better at capturing how running a digital service is an ongoing process.
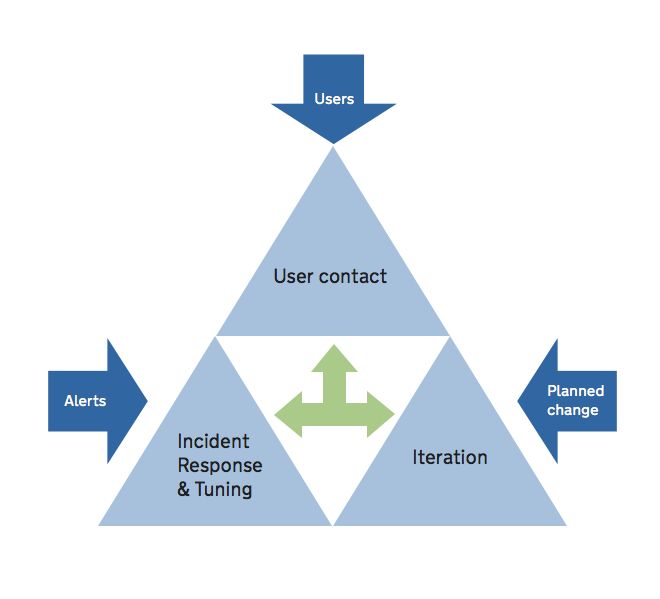
We divide this into 3 main activities:
- User contact – dealing with feedback
- Incident response and tuning – keeping the service alive
- Iteration – improving the service
(We've avoided using ITIL terms like 1st, 2nd and 3rd line support, which aren't descriptive and which are used inconsistently.)
1. User contact
User contact is the front-of-house for a service. It’s where you listen and respond to feedback from your users.
Users may want to say how good the service, how they struggled with it, or that they don't understand how to use it. They may also spot problems with the service, which can be passed to an incident response team.
We often work with other parts of our organisation to gather feedback from users. For example, the existing call centre for lasting power of attorney forms now handles questions and feedback on the digital service.
2. Incident response and tuning
A digital service is often a complex set of software systems that can be destabilised by anything from malicious attacks through to hardware failures.
You'll always need to have people with the right technical knowledge in place to react to these incidents.
It's also important to carry out 'tuning' to ensure you have:
- the right amount of alerts – so you don't miss important problems or get overwhelmed with noise
- readable code and documentation – so you can quickly understand unfamiliar systems
- effective tools to investigate problems – so you can diagnose what's gone wrong
Effective tools could include searching logs (hunting through a detailed history of what the system did) or graphing metrics (visualising how certain tracked values have changed over time).
To deal with all this, we've set up an incident response and tuning team. This runs during office hours and out-of-hours. Unlike many technical support teams in government, it's made up of engineers who work on a rota. This is so we keep a DevOps culture across the team, rather than having 2 separate teams for delivering and operating services, which could be at odds with one another.
3. Iteration
Services need to change all the time. This could be due to changes to the law, changing user needs, patterns in analytics data, the need to cut costs or simply because you want to make the service better for your users.
If you want a sustainable organisation, you'll need the time, budget and people to quickly deal with these demands and look after a porfolio of live services.
There are lots of ways that services can be iterated and improved: for example through frequent releases, regular automated testing, and some controlled chaos similar to Netflix’s simian army.
We've found iteration the hardest of the 3 activities to solve. At the moment, this work is being done by delivery teams for new products, which can use up to 1 day a week on improving existing services.
We intend to put together a multidisciplinary team dedicated to improving services. This would have to balance demands from a lot of different products, and avoid the temptation to take on major changes, which could compete with new projects.

How this changes the way we run services
When we write a business case, we encourage a long-term funding plan which includes estimates for the 3 activities (user contact, incident response and tuning, and iteration). We combine these with the cloud hosting costs to show the long-term cost of sustaining a service.
When it comes to planning, we don't allow a product team to move onto another project until there's a sustainable solution for each activity. This is a crucial part of our 'definition of done' for that team, though of course the product itself will never be completely done and dusted.
Finally, we're changing the way we organise our teams. We now encourage our technical professionals to move between iteration and incident response so they can experience both sides of sustaining services: making the services, and keeping them alive.
An engineer responding to incidents on new, less stable services will have an understanding of the compromises made to ensure rapid delivery. An engineer repairing a service is learning how to avoid the situation in the next service they build.
Let us know what you think
We're still learning how to make this model work, but it's already helping us to start solve some complex organisational, planning, and funding challenges.
Have you faced similar challenges in your organisation? Can you tell us how you tackled the problems? Or would you be interested in speaking to us about these ideas?
Please get in touch – we'd love to know what you think.
Like this blog? Keep posted: sign up for email alerts.

1 comment
Comment by David Durant posted on
This is excellent - I really hope this is referenced in the new revision of the GDS Service Manual as one strategy for how to work with post-Live services.