Last week we released two new beta services: Court and Tribunal Finder and Tribunal Decisions.
The Court and Tribunal Finder lets users find details of their local courts, while Tribunal Decisions provides a searchable list of all the important cases in immigration and asylum appeals.
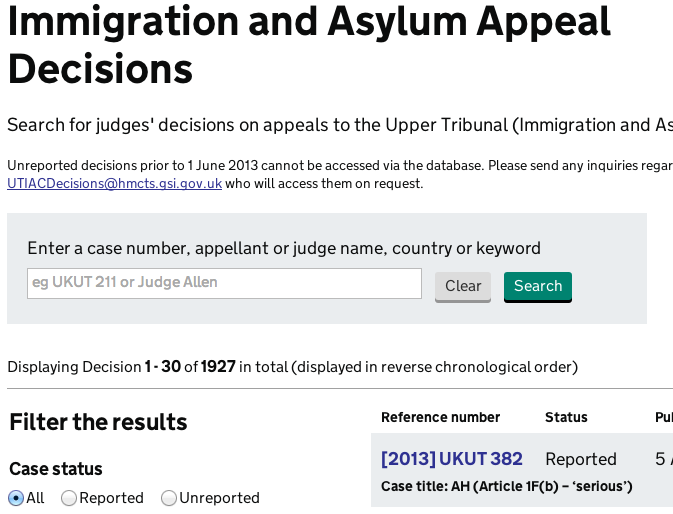
Those services aren't entirely new, as previous versions were already available, but we've improved them a lot: with a GOV.UK-style user interface, better search functionality, accessibility, and more. But here I'd like to focus on one invisible feature that we've also added: machine-readable markup.
Each court, tribunal or decision page now includes additional code that makes it easier for other web services, notably search engines, to ‘understand’ the page's content and reuse it, better than if they tried to ‘scrape’ the page, i.e. guess the meaning of what's on it. (More technical details are available on a separate page.)
The code is added to the page so that even if we modify the visual style of the page or its structure, the machine-readable information will remain unchanged. This saves scrapers (software applications extracting information from websites) from having to change their code when we alter the page.
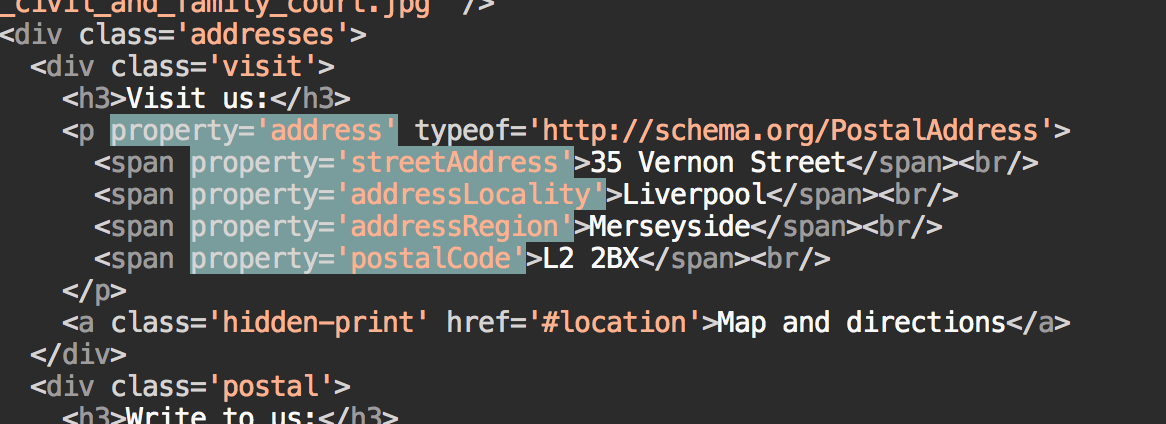
Adding that markup wasn't very difficult and needed little coding. Yet it will make it easier to fetch and reuse our data to improve online services.
We expect our new services to do more than help search engines. We'd like to see web services developers include our data in their own applications. Imagine a service that would link tribunal decisions with relevant legislation, for instance. Probably very useful for lawyers or journalists.
What's next? We'll be taking feedback of course and we hope that 'consumers' of our data will find creative ways to use our services. We'll then make further improvements: for instance, be a bit more specific when we describe tribunal decisions.
We'll also ensure our other informational services (like Find a Legal Adviser or the upcoming Form Finder) expose data in a similar fashion. And we'll make sure that all our data is linked to other datasets, as published by government or anywhere on the Semantic Web.
At DSD, we're proud that we're able to do our bit to implement the government's Open Data charter, especially when departments are working to define the National Information Infrastructure, which holds the promise that more and better data will be made available to the public.
We'd like to thank Dan Brickley and John Sheridan for their help in this work.
